
A Cloud Guru has been an entirely serverless company from day one.
The reason that Sam Kroonenburg chose serverless when building A Cloud Guru was to reduce the time to market. Five years later, serverless has been an incredible productivity booster for the organization. It’s enabled the dream of small and lean product teams delivering features to production multiple times per day. Serverless architecture means that these teams can spend less time managing infrastructure and more time building features.
But, as they say, there’s no such thing as a free lunch. In the case of serverless, that’s meant we have specifically had to architect our application to solve the performance issues that can come with it. The way we improved performance? Minimizing the impact of cold starts and the communication between lambda functions. Here’s how.
How we reduced the impact of Lambda cold starts and improved our lead times with GraphQL Schema Stitching
What’s a cold start? Here is an excellent explanation.
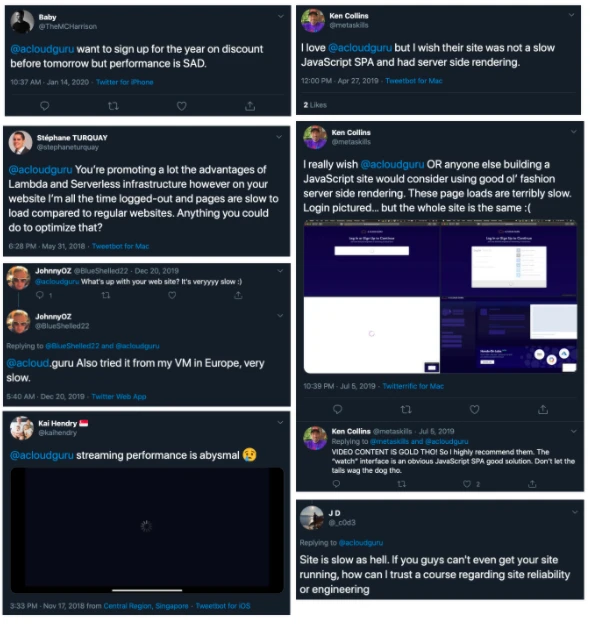
Feedback from students that performance is important
When it comes to managing the impact of cold starts, the first place to look is the request-response APIs that are driving frontend behaviour. In the case of A Cloud Guru, our API layer was written in GraphQL.
The slow responsiveness was the main reason we had looked into improving our GraphQL layer. As a secondary point, we wanted to improve developer happiness. This could have been done by reducing time to production (lead times). For common changes like extending or deprecating an API, we didn’t want for developers to make changes in two places, which could require additional deployments and code reviews for each step.
Let’s run through the evolution of our architecture and how those changes reduced the performance issues and improved our lead time.
A GraphQL primer using web series
The main appeal of GraphQL is to fetch all the data needed for a single page within one request. This decision was particularly important because we were also building our first mobile application at the same time. For GraphQL to be able fetch data within one request, there has to be a single endpoint that’s capable of resolving the entire application data graph. That entry point is our gateway. Our gateway is just used as a single point of entry and by design doesn’t contain business logic.
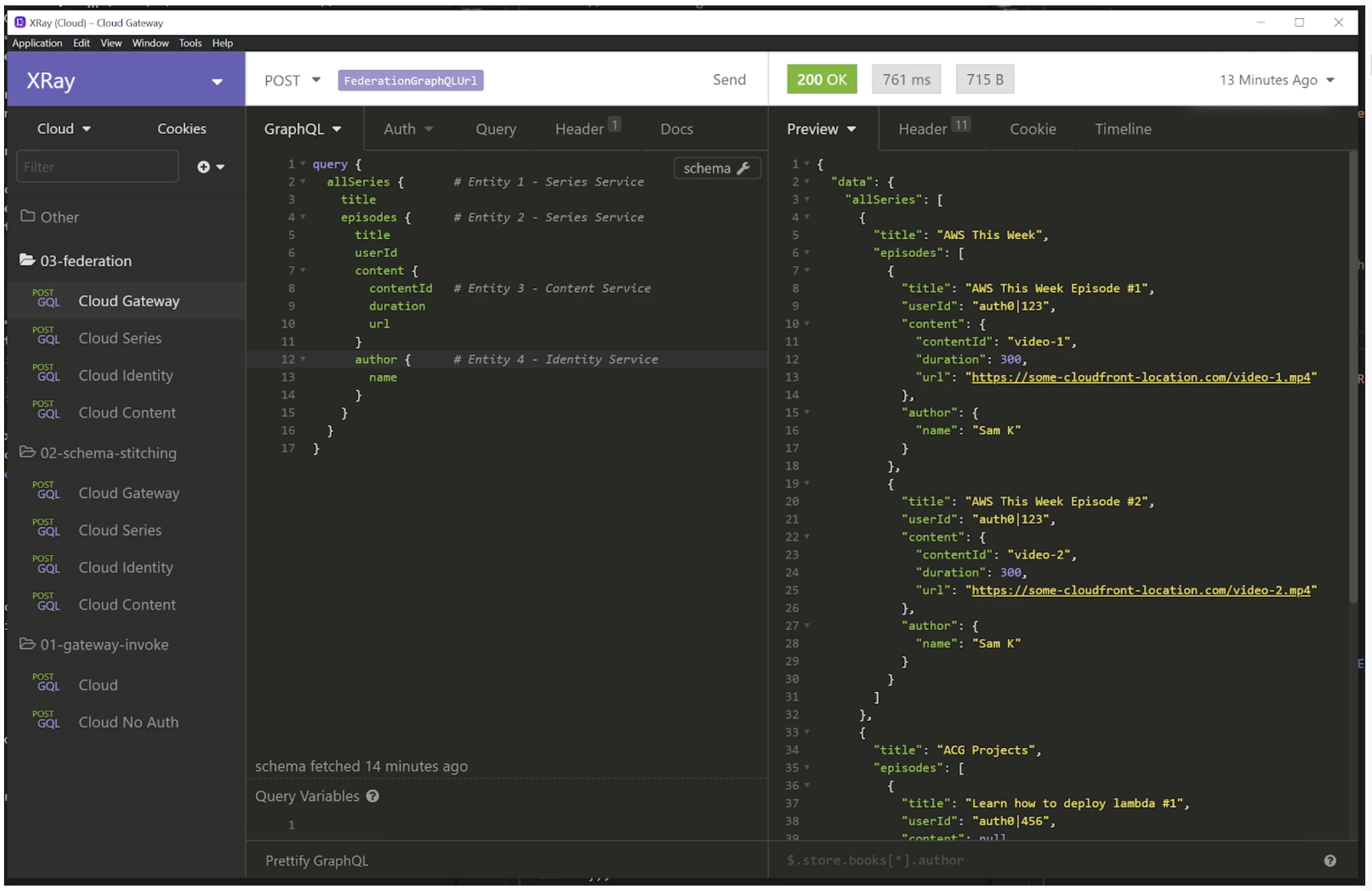
A typical request that would be used for loading our web series page. For example, this landing page.
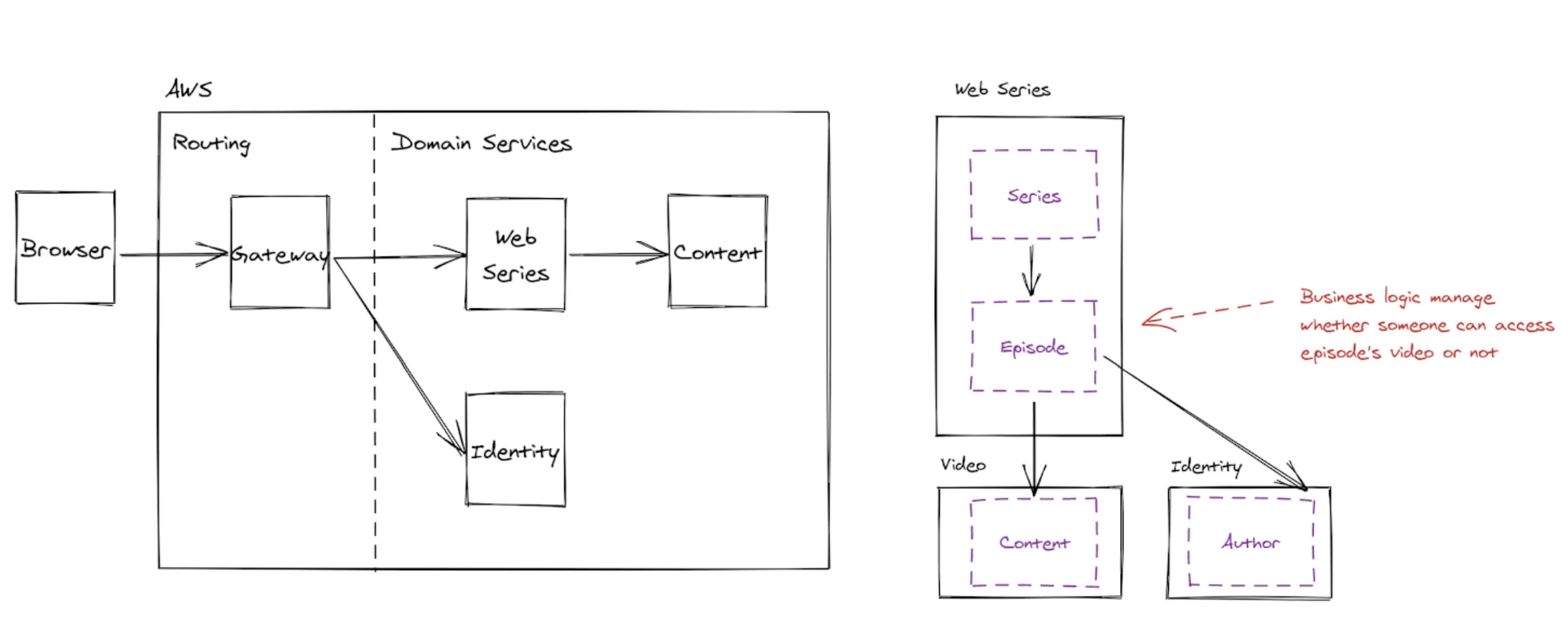
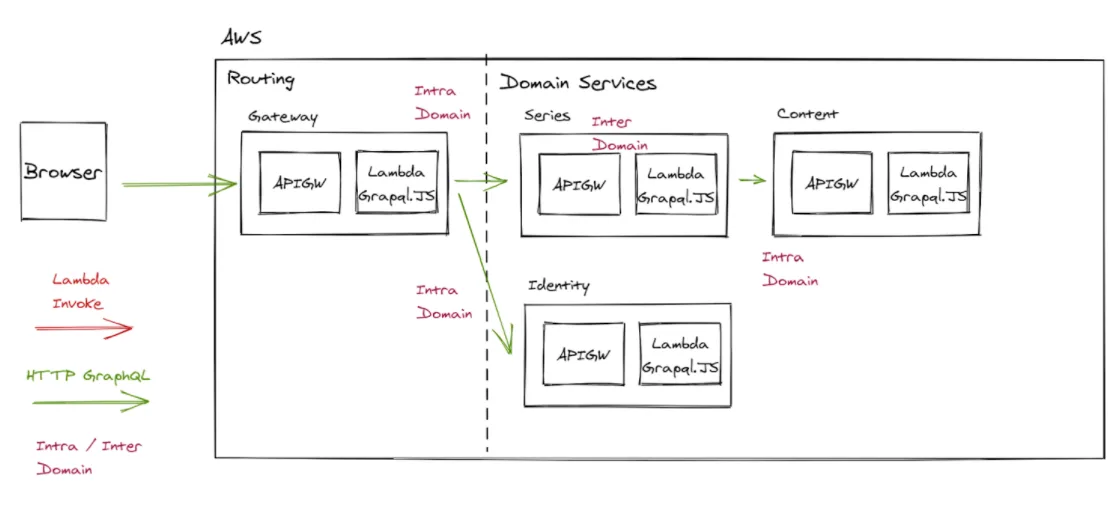
Systems architecture / entity association of microservices involved in resolving web series.
GraphQL is just a specification on the format of a query. It doesn’t prescribe some key details: where the schema definition should exist, how the data is resolved within a microservice (intra-domain), and how data is resolved between a service (inter-domain). Two different architecture approaches adjust these two variables.
Lambda functions invoked by a Graphql gateway
Location of schema definition: Located on the gateway
Data resolution: Gateway performs Lambda Invokes into the Microservice to resolve data; gateway owns intra and inter type connections.
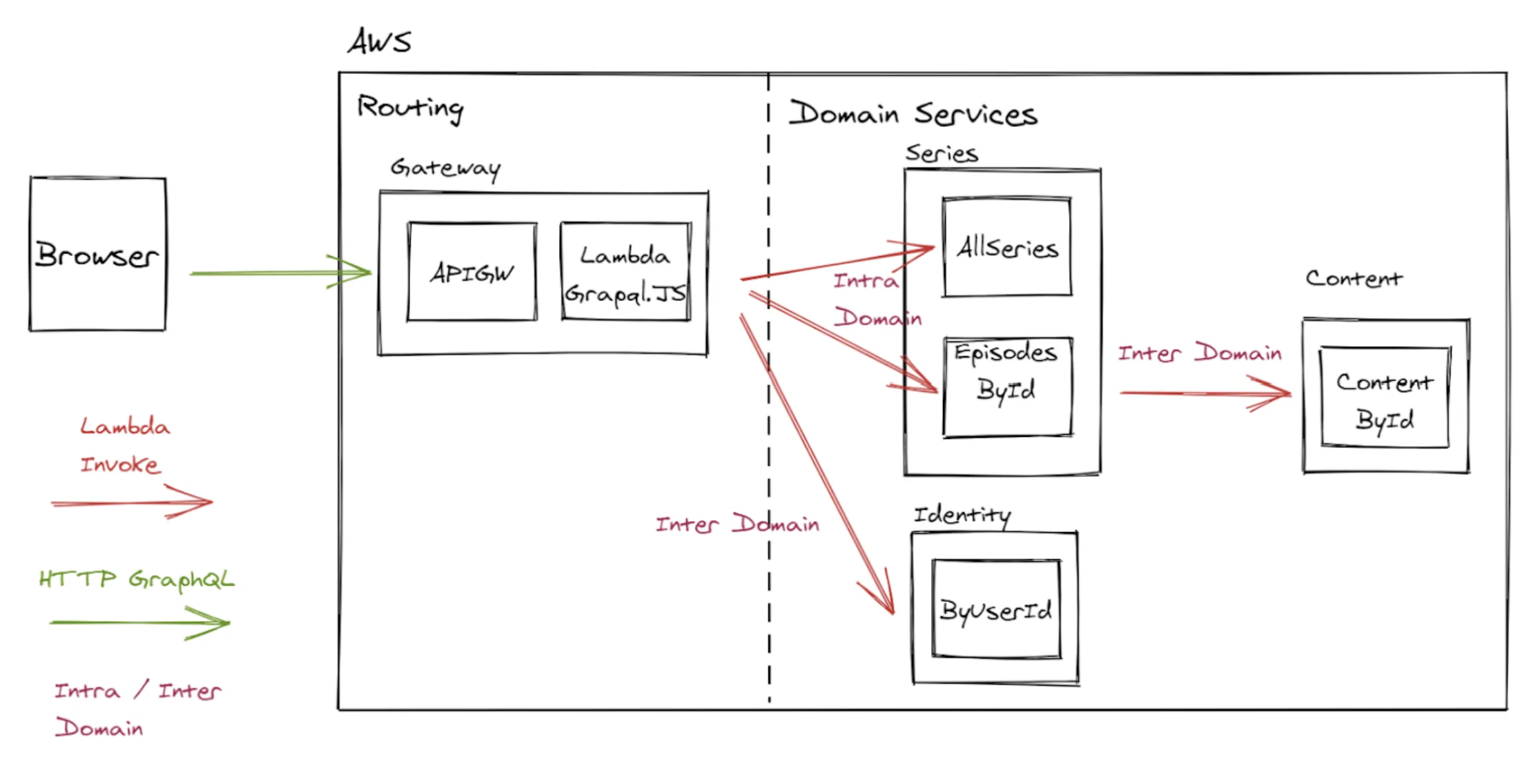
Service to service was managed through AWS SDK Lambda Invoke.
This architectural approach just used GraphQL.js on the gateway. This gateway would own the entire schema and manage the resolution of queries into our backend. That way the gateway would reach out into each microservice using the AWS SDK’s Lambda Invoke.
1const response = await lambda 2 .invoke({ FunctionName: 'series-dev-allSeries' }) 3 .promise(); 4 5return getInvokeBody(response);
An example AWS Lambda Invoke call the the gateway would make. Reference
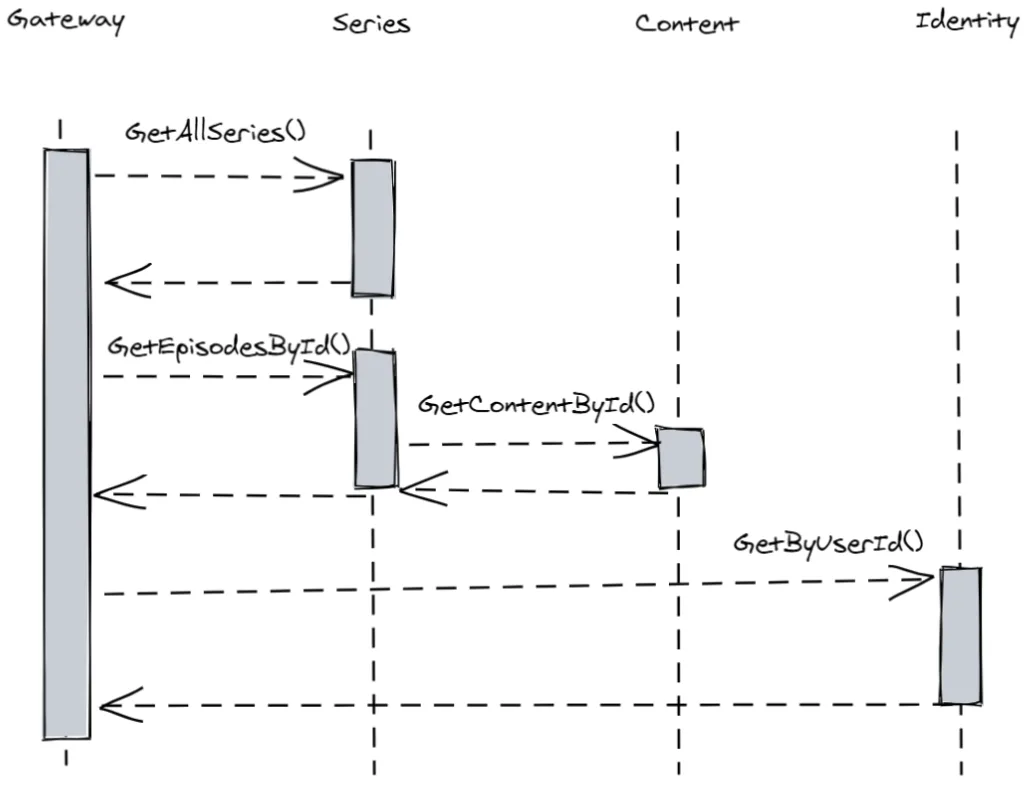
Data resolution for query is orchestrated by the gateway.
The resolution of the data is as follows:
The gateway resolves all the series
- When the series is known, the gateway then asks for all the episodes within the series
- Due to the episodes entity owning access permissions, it has the business logic on whether someone should see the episode or not
- Once the resolution of the episodes happens, only then can the gateway resolve the author from our identity service
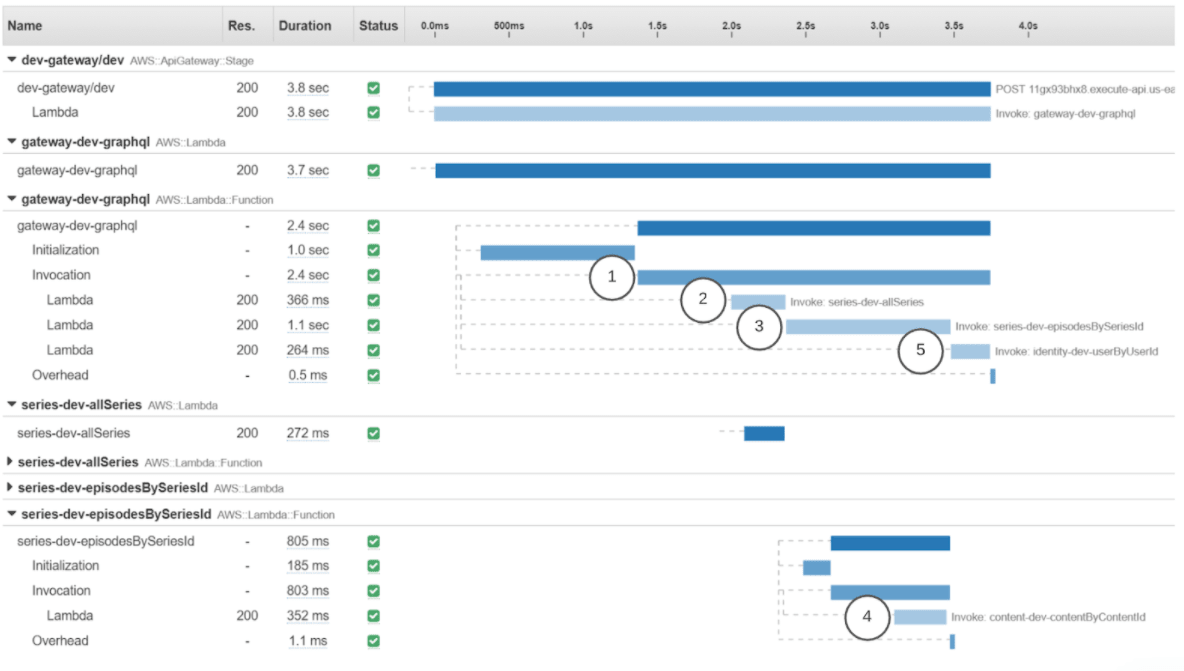
A sequence diagram illustrated with XRay. Series + Identity called on gateway, and content called on series.
XRay illustrates two key things: the time it takes to initialize a cold lambda function, and how long it takes to fetch the data. The initialization only has to happen once per lambda container, as the same container is re-used for subsequent requests (until scaling up or the container gets recycled).
What we noticed with this query is that it crosses five lambda functions to resolve all of the required data. There are two types of lambda functions: lambda functions that are invoked frequently (gateway lambda) and lambda functions that may not be (2x Series, 1x Content, 1x Identity).
The example above is the best-case example for the lambda functions. (They are light on code dependencies because code dependencies introduce longer cold starts.) In the typical example, most lambda cold starts are around one second. This means a user hitting the page where four lambdas aren’t warm (haven’t been invoked in 15 minutes) could be experiencing a five-second delay. Ouch.
There are a couple of other problems with this architectural approach:
- The GraphQL schema exists on the gateway. This requires two deployments when changing an API — increasing lead time and decreasing developer happiness
- Communication is coupled to Lambda, meaning we wouldn’t be able to have microservices that don’t use lambda functions. (This turned out to be important when integrating Labs and Playgrounds from the Linux Academy Platform.)
Schema stitching
Location of schema definition: In each microservice
Data resolution: Gateway delegates query resolution to microservices; gateway owns inter domain type connections; microservices own intra domain type connections.
Now communicating from the gateway to the downstream services using schema delegation / stitching. RPCs also managed through connecting via GraphQL.
1const mergedSchemas = stitchSchemas({ 2 subschemas: [ 3 seriesSchema, 4 contentSchema, 5 identitySchema 6 ], 7 typeDefs: ` 8 extend type Episode { 9 author: User 10 } 11 `, 12 resolvers: { 13 Episode: { 14 author: { 15 selectionSet: `{ authorId }`, 16 resolve(episode, _args, context, info) { 17 return batchDelegateToSchema({ 18 schema: identitySchema, 19 operation: 'query', 20 fieldName: 'usersByIds', 21 key: episode.authorId, 22 argsFromKeys: (ids) => ({ userIds: ids }), 23 context, 24 info, 25 }); 26 }, 27 }, 28 } 29 } 30}); 31 32const response = await graphql( 33 mergedSchemas, 34 payload.query 35);
Stitching the schemas together and doing a cross domain link between episode and author entities together on the gateway. Reference
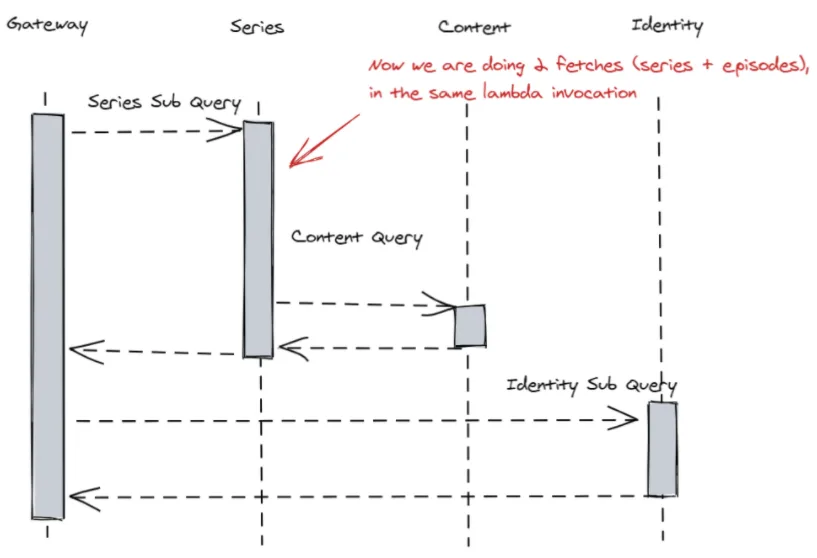
We delegate sub queries to responsible microservices
The resolution of the data is as follows:
- The gateway delegates the web series portion of the query to the series service
- Due to the episodes entity owning access permissions, it has the business logic on whether someone should see the episode or not, so it still manages the resolution of the content service
- Once the resolution of the episodes happens, only then can the gateway delegate the resolution of authors through the identity service
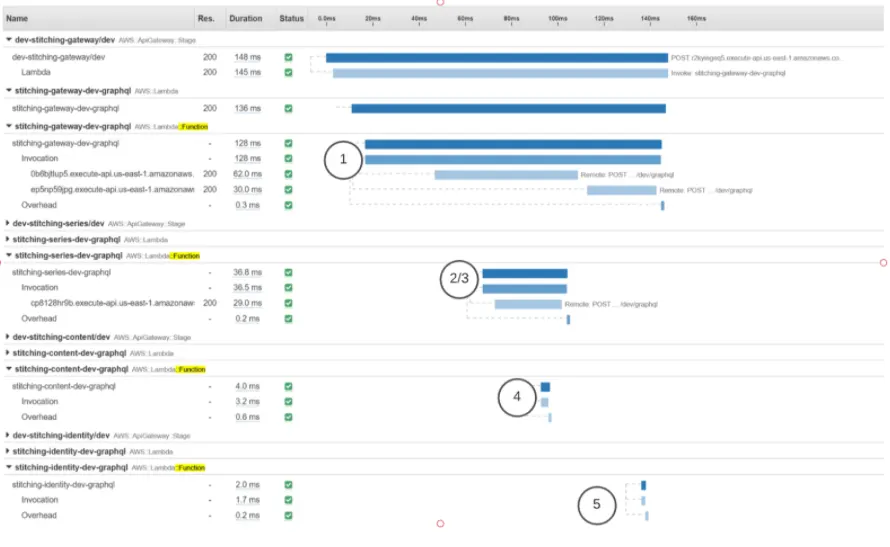
Sequence diagram illustrated with XRay. Series + Identity called on gateway; content called on series. Cold-start initialization omitted due to the likeliness of the lambda being warm.
Using this approach, each microservice’s API is now represented as a single lambda function. This does two things:
- Intra domain connections (e.g. series + episodes resolution happens within the same lambda function rather than across two). This reduces the number of possible starts + service to service invocation time
- The lambdas are likely going to be warmer because there is only one lambda function for an entire service
We have transitioned from five possible cold starts down to four (gateway, series + episode, content, author), though each lambda is less likely to have a cold start as the API lambda is handling lots of different operations for that microservice.
Transitioning from the gateway owning the schema to schema stitching has solved some of the issues in the first approach:
- Changes to the API and service can be done in one deployment, improving our lead time
- No longer coupled to AWS lambda as we are using HTTP to communicate
This approach did have some problems, though it came with some trade-offs:
The gateway still had to manage inter domain connections (albeit, less likely to be in comparison to intra connections)
- Additional latency was added by using API Gateway (could have technically still been done with Lambda Invoke)
- Security is managed by x-api-keys rather than IAM
Monitoring became harder because there is one GraphQL lambda for all the API requests a service handles. We had decided to use a GraphQL specific service to solve this problem (Apollo Engine). Adding an additional service does mean that we now have multiple places where you can search for issues with API requests.
For the gateway to know how to delegate the request microservice, we have to query every microservice. (At this point we had over 40.) Querying service microservice would introduce either a longer cold start OR cache invalidation problems. We ended up solving this problem by adding in-house service discovery. Every time a request came in, the gateway would make a single request to the service discovery tool to get the entire schema, url and api keys of each microservice. Note: Service discovery is not included in the example code, adding three additional introspection calls.
Cold start analysis
To compare the different approaches, we used ApacheBench and then exported the results into Excel. To capture the effects of cold starts, all functions were re-deployed before. A consideration is that this ApacheBench test is completely synthetic (all at once) and not indicative of real-world traffic (staggered over the day).
1# Force coldstarts 2./deploy.sh 3 4# Run tests 5ab \ 6 -n 1000 \ 7 -c 5 \ 8 -T "application/json" \ 9 -p "post-request.json" \ 10 -g "gateway-invoke-results.tsv" \ 11 "https://11gx93bhx8.execute-api.us-east-1.amazonaws.com/dev/graphql"
ApacheBench running performance testing Reference
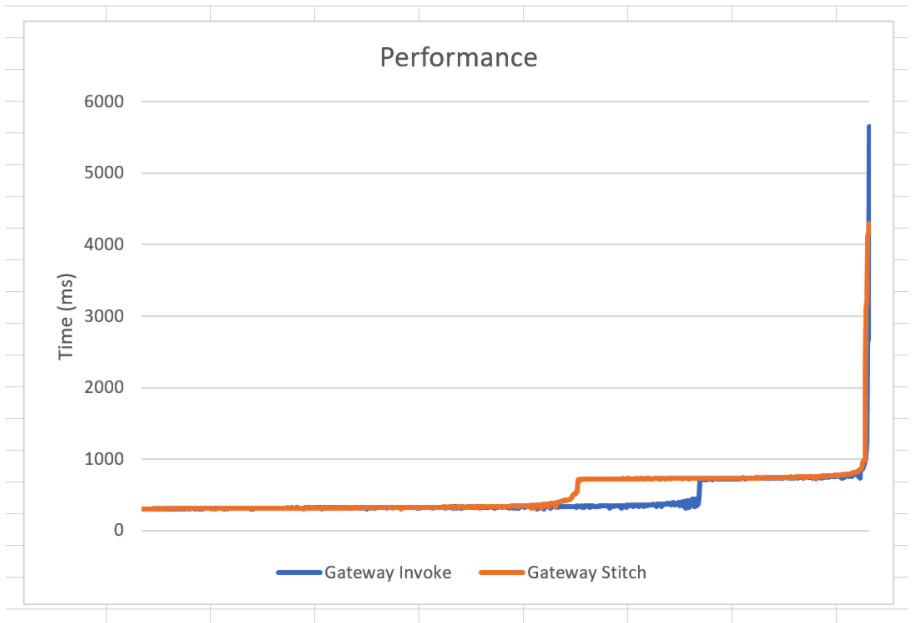
Gateway Invoke vs. Schema Stitching Raw Results
There appear to be two key differences in the results of the data.
In this specific query schema, stitching has a 20% lower p99 (five seconds to four seconds). The lower p99 is due to one less lambda function invocation / cold start when resolving the series data. What can’t be easily shown in synthetic tests is the reduction in cold starts due to the lambda functions being kept warm by other calls made to these microservices. We would suspect there’s a higher utilization of that single API lambda function compared to the many lambda functions that the gateway approach has. This would mean significantly fewer cold starts over time.
Gateway Invoke performance is better between the p60-p70 mark. In the schema stitching approach, we introduced API Gateway when communicating between microservices. It appears that adding API Gateway adds additional variance to the results. If we had decided to continue to use lambda invoke for schema stitching rather than API Gateway, this might have reduced that inconsistency.
Lead time analysis
It is a little harder to pin-point the exact amount of API changes that are happening to our gateway. Though, we can do some rough calculations by using data pulled from our Apollo Studio changelog. We can see that in the Month of September, we had roughly 230 changes to our GraphQL schema.

Apollo Studio calculating GraphQL schema diff
By looking at what’s contained within the diff, it would appear that there are roughly 20 deployments that have a schema change within them. It wouldn’t unreasonable to think a schema change could take around three engineering hours, a PR (context switch for the other engineer reviewing the code) and to deploy the gateway. That means we could have potentially saved 60 hours per month by bundling and deploying schema changes along with code changes.
Conclusion
With the goal to improve the overall student experience, we’ve made some significant architectural changes.
Schema stitching allowed for fewer cold starts, and when they did happen, they would have a lower impact (at least 20%). Moving to schema stitch also had a large reduction in the lead time to get an API change from development to production (across all our engineers, roughly 60 hours per month).